Appearance
Finding Methodology
Blackridge does not ask you to trust its conclusions — it publishes how every finding is computed so you can audit the reasoning. This section documents, for each finding type: the claim it makes, the detection logic, the evidence attached, the cost math, and the limits of what it can prove.
Principles that apply to every finding
Realized vs modeled, never mixed. Every dollar figure carries a basis label:
| Basis | Meaning | May be booked as savings? |
|---|---|---|
REALIZED WASTE | Cost already incurred, supported by observed events | It is a loss, not a saving — it measures what remediation removes going forward |
MODELED OPPORTUNITY | Estimated saving if behavior changed; did not happen | No — validate first |
SIMULATED WHAT-IF | Counterfactual result from a simulated policy change | Never |
EVIDENCE GAP | A data-quality finding about missing signal | n/a |
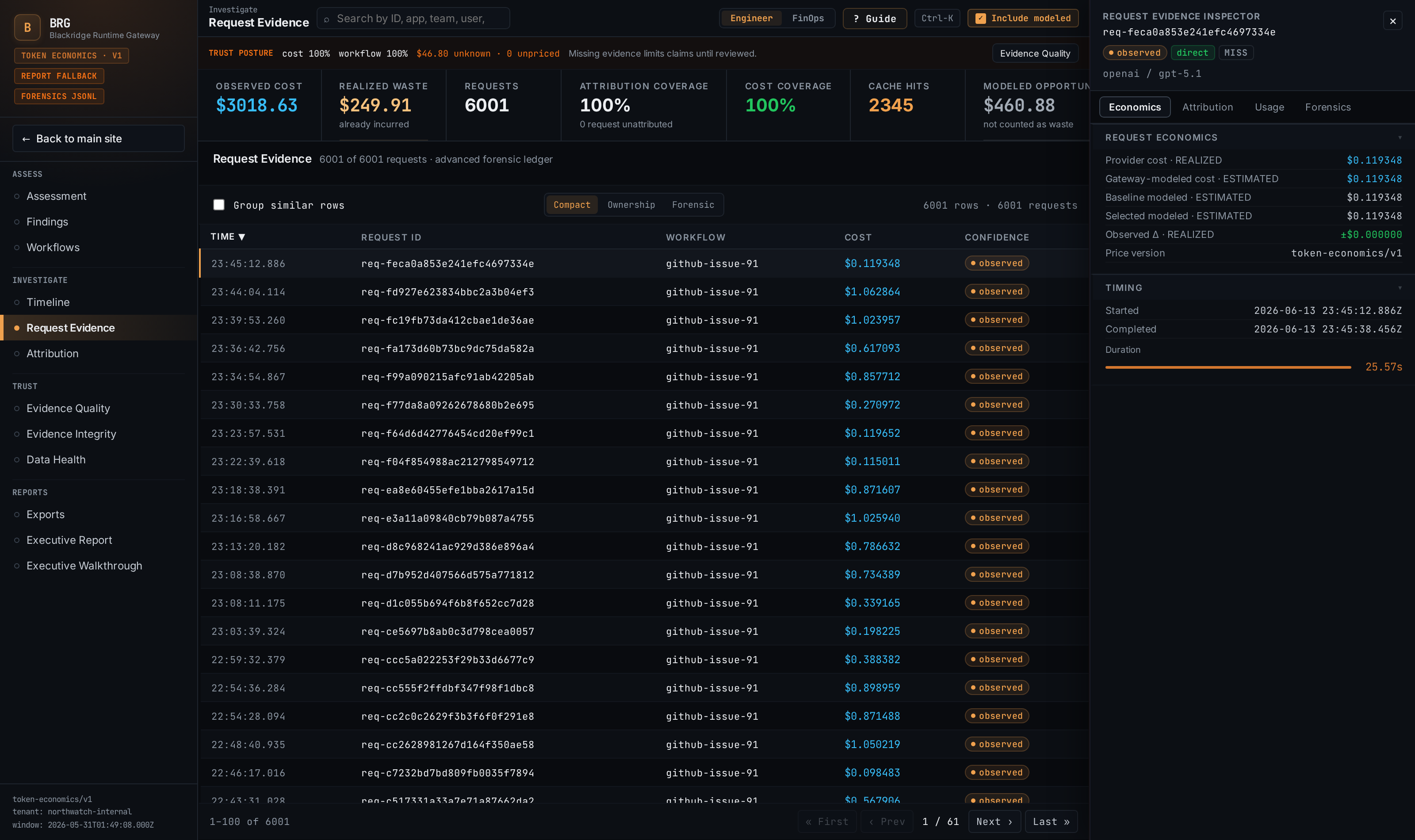
Evidence grades. Every claim and evidence row is graded: OBSERVED (directly captured from a provider signal or canonical event) → IMPORTED → DERIVED (computed from observed signals) → INFERRED (indirect signals; verify before finance or policy action) → SIMULATED (did not happen). A finding's grade is the weakest grade among its supporting evidence.
Unknown is not zero. Missing pricing does not mean zero cost; missing attribution does not mean an assumed owner. Findings report their unknown coverage (missing cost, attribution, usage, or pricing rows) alongside the claim instead of silently excluding it.
Deterministic and reproducible. Findings are computed deterministically from canonical records — never from other derived artifacts. Each finding records the algorithm version, pricing snapshot version, and a reproducibility hash, so re-running the analysis over the same events yields the same claim.
Finding types
| Finding | Basis | One-line claim |
|---|---|---|
| Retry amplification | Realized | The same work was billed more than once due to retries |
| Failed request waste | Realized | Requests that failed still incurred provider cost |
| Abandoned branch waste | Realized | Agent branches that never contributed to the final output were billed |
| Fallback tax | Modeled | Fallback routing completed requests at a higher cost than the expected primary path |
| Cache miss opportunity | Modeled | Repeated requests could have been served from cache |
| Semantic duplicate waste | Modeled | Distinct requests performed semantically equivalent work |
| Unknown / unattributed spend | Evidence gap | Spend that cannot be priced or assigned to an owner |
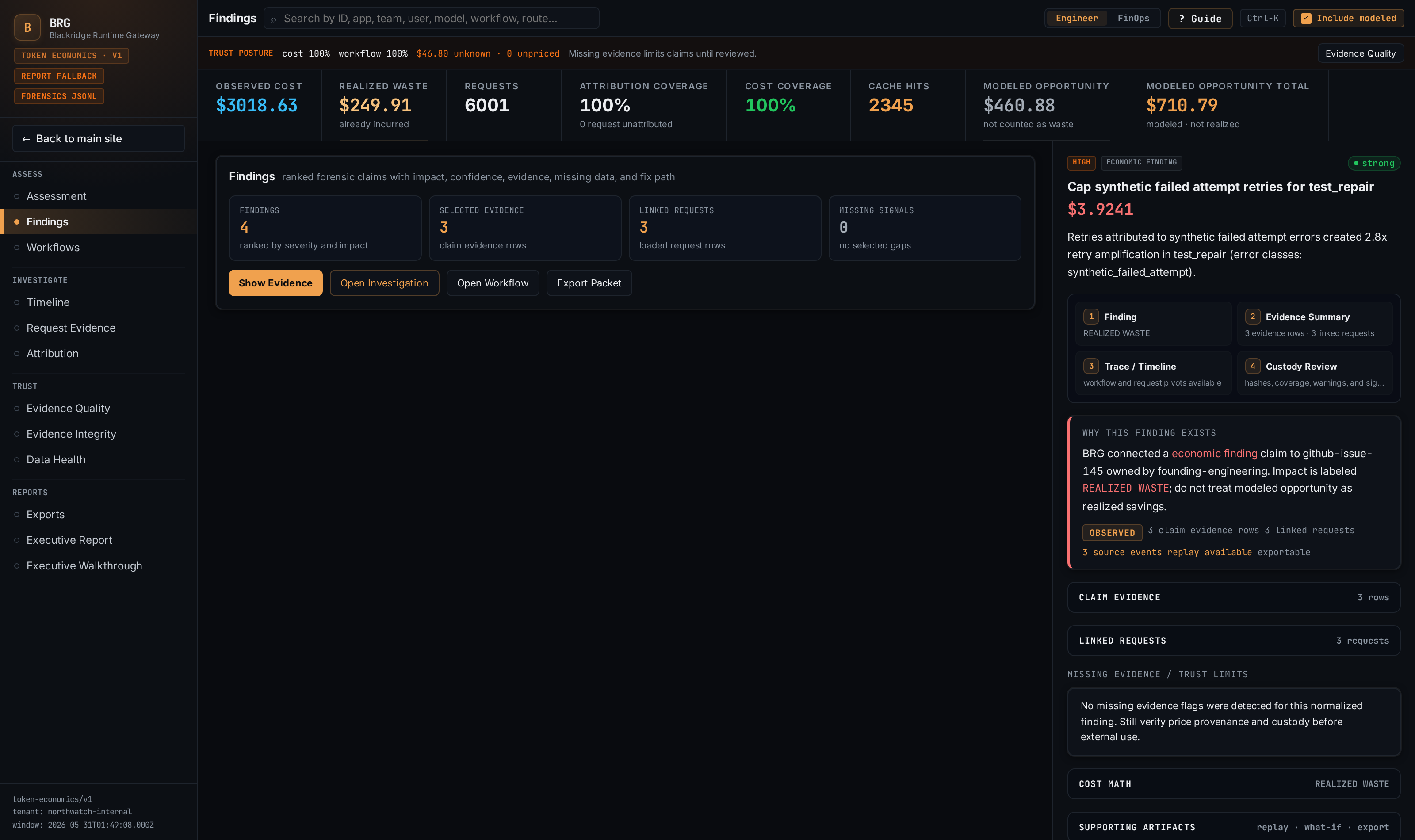
How to read a finding
Every finding is presented in four layers:
- Claim — plain-English statement with impact and basis label.
- Evidence summary — supporting evidence rows, linked request IDs, source event IDs, price provenance references, and missing-signal flags.
- Trace — the request chain, timeline window, or workflow replay the claim is drawn from.
- Raw — the underlying records, exportable body-free.
A finding without request-level evidence rows is labeled as aggregate or external evidence and should not be used externally until source rows load.